A brief introduction to MDPs¶
Welcome to the world of Markov Decision Processes (MDPs)! MDPs are a fundamental concept in the field of artificial intelligence and reinforcement learning. They are widely used to model decision-making problems where an agent interacts with an environment to maximize some notion of cumulative reward.
What is an MDP?¶
A Markov Decision Process (MDP) is a mathematical framework used to model decision-making problems in which an agent interacts with an environment over a series of discrete time steps. At each time step, the agent observes the current state of the environment and selects an action. The environment responds by transitioning to a new state and providing a reward signal to the agent. Importantly, the transition to the next state and the reward received only depend on the current state and the action taken, satisfying the Markov property.
Key Components of an MDP¶
States (S): The set of all possible situations or configurations in which the agent can find itself.
Actions (A): The set of all possible moves or decisions that the agent can make in a given state.
Randomness/ Events In certain situations, the next state and reward do not depend deterministically on the state and the action, but are stochastic. In DynaPlex, the random events or stochastic transitions are represented by random variables that are explicitly sampled from some distribution.
Transitions: Transition function specify how the state changes in response to actions and randomness/events.
Costs: The numerical values associated with state-action pairs, indicating the immediate cost of taking a particular action in a specific state. Note that a reward is a negative cost.
A key related concept is that of a policy, which specifies the action to take in each state:
Policy (π): A strategy that specifies which action to take in each state.
DynaPlex builds on the MDP-EI (MDP with exogenous inputs) framework, which is illustrated below. Here, \(s_t\) represents the state at time \(t\), \(\pi\) represent the policy, \(a_t\) the decision, and \(c_t\) the costs. We further denote a random event by \(\xi_t\) and the transition function is \(f\). For more information, we refer to: ArXiv paper, A unified framework for stochastic optimization. See also the published version of the Deep Controlled Learning paper: published version.
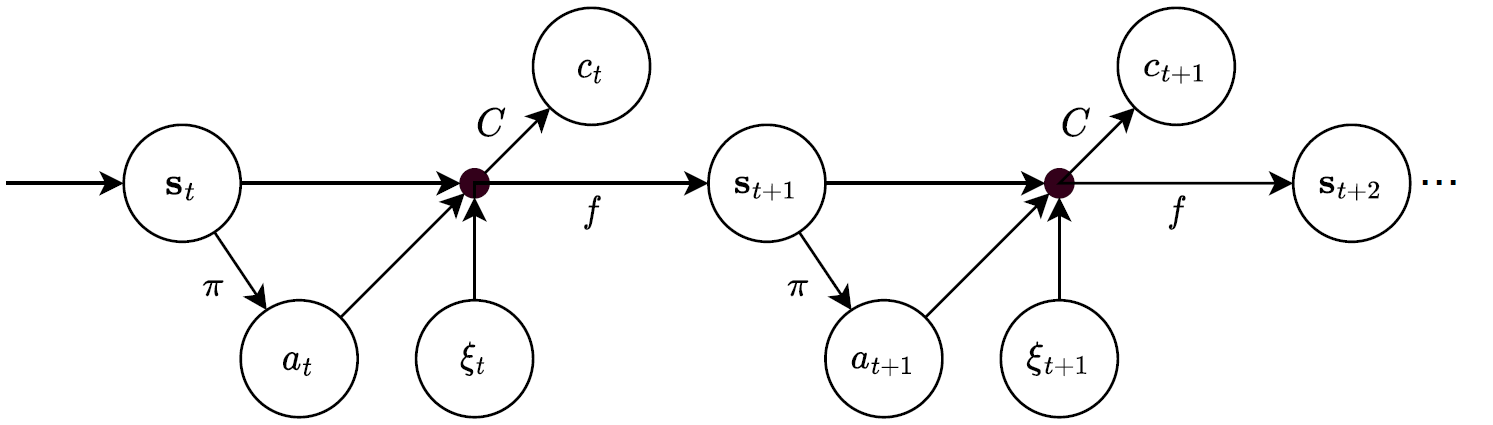
MDP models in DynaPlex¶
DynaPlex models are defined as an MDP dataclass. This dataclass has specific methods which are required, and which manipulate objects of another user-defined class that represents the state of the problem. The formalization makes an explicit distinction between States that are awaiting an action (pre-action state) and States that are awaiting an event (post-action state); cf. “Reinforcement Learning and Stochastic Optimization” by Warren B. Powell, Section 3.3.
We provide examples/tutorials in the form of the Airplane Ticket Selling MDP and the Bin Packing MDP: Airplane Ticket Selling MDP and Bin Packing MDP. The Python code for these MDPs is available in the Airplane MDP Python Code and Bin Packing MDP Python Code pages.
Classes and methods in DynaPlex MDPs must adhere to certain structural and semantic properties. For more information, see the Language Reference.
Recommended Reference Books¶
For further exploration of Markov Decision Processes, we recommend the following books:
“Markov Decision Processes: Discrete Stochastic Dynamic Programming” by Martin L. Puterman. - This book offers a thorough treatment of MDPs, including dynamic programming methods and their applications.
“Dynamic Programming and Optimal Control” by Dimitri P. Bertsekas. - A comprehensive reference covering dynamic programming techniques, including their application in solving MDPs and optimal control problems.
“Reinforcement Learning and Stochastic Optimization” by Warren B. Powell. - A valuable resource that explores the intersection of reinforcement learning and stochastic optimization, providing insights into advanced techniques.